Date: 09-Jan-2022
Time: 02:00:00 PM
Author: Shashi Kant Mani
How does Google Search Engine work?

Google Search Engine:
Developed in 1997 by American Computer Scientists, Larry Page and Sergey Brin, Google Search Engine is the biggest search engine in the WWW. As of now, is handles about 3.5 Billion Searches per day[#1] indexing hundreds of terabytes of information. It holds 92% share of the overall search engine market. Google is on top of the most visited websites in the world.
How does is work?
Google Search Engine architecture has the following major components-
- User Interface
- Query Engine
- Crawl Controller
- Page Repositories
- Indexer Module
- Collection Analysis Module
- Page Rank System
Consider the diagram:
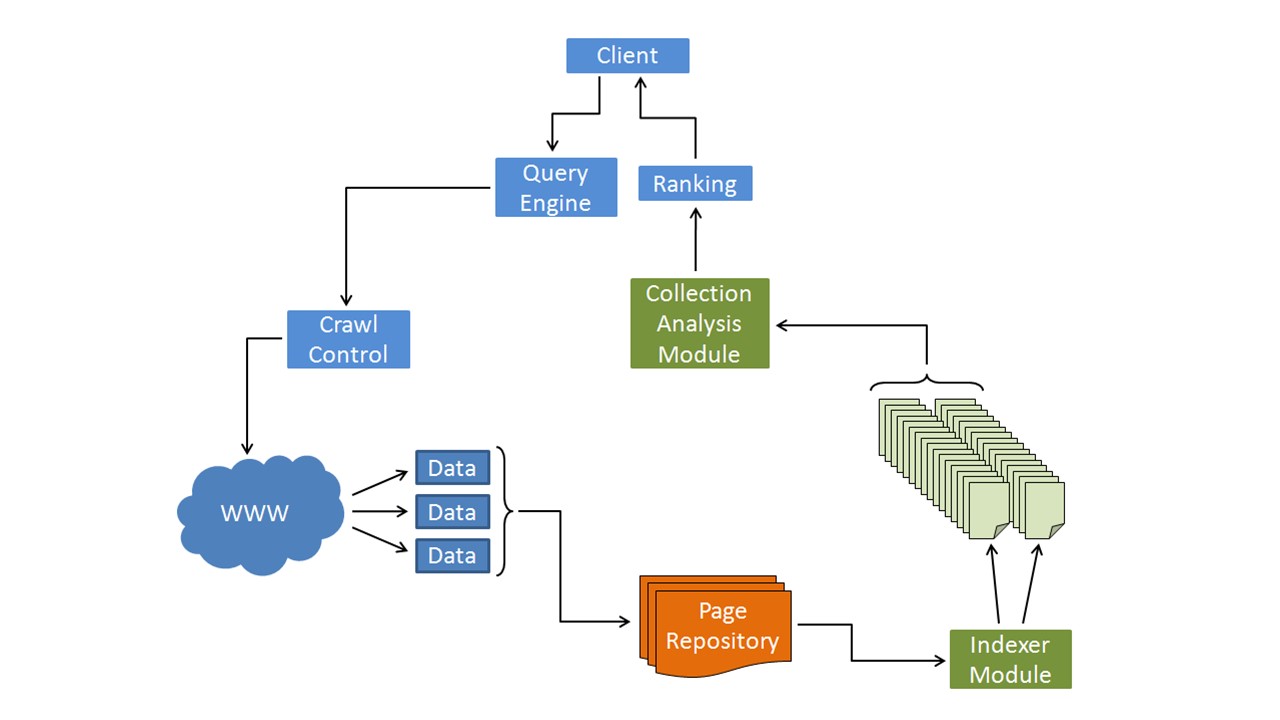
-
User Interface: It is the classic Google page that appears after we hit www.google.com in the browser. User type in the search words or phrases here in the search bar.
-
Query Engine: Query Engine is one of the most intelligent software designed by Google. Not only it starts predicting what is being typed in, it also tries to get the intent of the query. It manages to do so by:
- Understanding Language
- Understanding Script
- Understanding Grammar
- Understanding Synonyms and antonyms
-
Crawl Controller: While most of the search engines use one or two crawlers, Google uses an entire army of crawlers. This is the reason, Google has its own crawl controller as well. Crawl controller assigns task of searching a particular types of information to a set of crawlers. Crawlers, then crawl through the entire WWW and find relevant data individually.
-
Page Repositories: Page repository is a temporary database that is used to keep all the searched websites and their relevant information as provided by the crawlers. Everytime we search something, a page repository is created and after we are done with the search, it is dissolved.
-
Indexer Module: Indexer module creates an index keeping aside the websites having a particular type of data. Thus all the websites having text similar to the keywords are kept aside. All the websites having images similar to the keywords are kept aside and so on.
-
Collection Analysis Module: This module extracts a short link from the websites that are to be presented as the search ressults. It also keeps that classification of information type hence we get all text results together, all the image results together an so on.
-
Page Rank System: Page Rank is basically an algorithm named after one of the co-founders of Google- Larry Page. It determines the importance of a website based on its PageRank points thereby sorting all the websites in a most important to least important arrangement. Once its all done, the reults are shown to the user.
#1 - Information referenced from Wikipedia;